Reading time:
3
min

Do you actually understand the ROI on your AI usage? Do you know how token usage corresponds to meaningful impact? At Bigspin, we are on a quest to answer these questions internally. This past week we ran an experiment focused on our design to development process.
Currently, the team uses a mix of Figma screenshots and Figma MCP fed to Claude Code to develop our designs. MCPs are known to be rather token hungry. We hypothesized that the screenshot method would be less token intensive and therefore cheaper.
Pretty quickly we were proven wrong. Not only was the Figma MCP superior in terms of speed to shippable design and cost, but it improved the engineer and designer experience. Before we get into those details, let’s walk through our methodology.
Two Bigspinners, Megan and Madeline ran the experiment. Both participants uphold high benchmarks for shippable deliverables and maintain a meticulous attention to detail.
The methodology
3 unique designs that leverage our design system. Though none of them represent any designs that had been previously developed. (We didn’t want AI to be able to cheat.)
In testing, we each ran both a Figma MCP and Figma screenshot version of every design.
For each design, we used the exact same seed prompt. The only variable in the initial prompt was whether Claude was to reference a screenshot or use the Figma MCP. Subsequent exchanges with Claude were unique, as it is a non-deterministic process, and our outputs varied.
The design output had to be one that passed both participants' quality bar. Both participants signed off on a design output before completing an experiment.
Once a design output was approved, we asked Claude for the following metrics:
Total token usage for the session
Total turn count
A breakdown of token usage by turn
Total cost
Skill files were used
Turns to completion — total user/model back-and-forths until the design is "good enough"
User time to completion — session duration / total active time (ROI here is both token cost and developer time saved)
Correction burden — how many times I had to restate context, re-upload a screenshot, or correct something you missed
On Day 1, (designs 1+2), we ran the experiment within our app repo. This gave Claude access to skill files. On Day 2, (design 3), we created a standalone repo where Claude had no access to skill files or any priors.
The overall findings
Figma MCP was the clear winner. It used fewer tokens, was cheaper, and was simply faster. And, it led to a lower cognitive tax than the screenshots flow.
The correction rounds with Claude in the screenshot-only flow became genuinely annoying. It required re-attaching the screenshot, using additional words, and even drawing arrows and lines on the screenshot to ensure it really knew where to make changes. This was almost never required with the MCP flow.
However, when comparing MCP vs screenshot in the absence of a codebase to reference, the cost/token usage is comparable, but MCP is still faster and lower-touch.
Here’s the full breakdown of numbers across the two-day experiment:
Day 1 - Bigspin repo with skill files (n=4 each)
Metric | Screenshot (avg) | MCP (avg) | Difference |
|---|---|---|---|
Total tokens (avg / session) | 23.4M | 13.0M | MCP ~45% fewer |
Cost - normalized to 4.8 (avg) | $23.23 | $15.29 | MCP ~34% cheaper |
User correction rounds (avg) | ~4.3 | ~0.75 | MCP ~5-6x fewer |
Wall-clock time (avg) | ~50 min | ~36 min | MCP ~28% faster |
Day 2 - bare repo, no priors (n=2 each)
Metric | Screenshot (avg) | MCP (avg) | Difference |
|---|---|---|---|
Total tokens (avg / session) | 18.6M | 20.1M | ~tied (screenshot slightly fewer) |
Cost - normalized to 4.8 (avg) | $20.28 | $21.15 | ~tied |
User correction rounds (avg) | 1.0 | 0.5 | MCP fewer |
Wall-clock time (avg) | ~52 min | ~40 min | MCP ~23% faster |
All 12 sessions pooled (n=6 each)
Metric | Screenshot (avg) | MCP (avg) | Difference |
|---|---|---|---|
Total tokens (avg / session) | 21.8M | 15.3M | MCP ~30% fewer |
Cost - normalized to 4.8 (avg) | $22.24 | $17.24 | MCP ~22% cheaper |
User correction rounds (avg) | ~3.2 | ~0.67 | MCP ~5x fewer |
Wall-clock time (avg) | ~51 min | ~37 min | MCP ~26% faster |
Costs normalized to Opus 4.8 standard rates ($5/$25 per M in/out, $6.25 cache-write, $0.50 cache-read). Sessions reported on stale $15/$75 rates (or a 1-hour cache-write at $10/M) are recomputed at the standard card for comparability; original figures shown as-reported.
Findings by metric
1. Total token usage
Screenshot sessions averaged 23.4M tokens (range 10.7M-30.7M); MCP averaged 13.0M (range 9.3M-20.6M). In every session, cache reads were ~90-96% of all tokens - the growing context re-read on each agentic step - so raw token counts are dominated by session length, not fresh work. MCP's shorter, lower-correction sessions translate directly into fewer cached re-reads.
2. Total turn count
Screenshot sessions ran 5-11 user turns (median ~7-9), with multiple visual-correction turns. MCP sessions ran 4-9 user turns, but most MCP turns were scoping/QA rather than corrections - the build itself typically landed in one turn after scope approval.
3. Token usage by turn (per session)
The pattern is consistent across methods: turn 1 is research/exploration, the build turn is the single largest spend (often 40-80% of the session because it runs build, lint, typecheck, dev server, self-review), and refinement turns are comparatively cheap. The difference is volume: screenshot sessions stack several refinement turns; MCP sessions usually have one or none.
Examples: Screenshot session A spent its biggest (build) turn at 12.36M turn-total tokens, then added six more top-bar polish turns. MCP session F spent 10.5M on the build turn, then just one 2.3M tweak turn (24px margin + Publish icon) before LGTM.
4. Total cost (normalized to Opus 4.8)
Screenshot averaged $23.23/session; MCP averaged $15.29 - MCP ~34% cheaper. Important: four of the eight original reports (C, D, G, H) computed cost on stale $15/$75 rates, which roughly triples the cache-read line (~95% of all tokens). Report E even flags this directly. Normalizing every session to Opus 4.8 rates changed the picture substantially (e.g. C: $63 -> $21; G: $33 -> $11; H: $23 -> $8). The as-reported figures are footnoted in the per-session table below.
5. Skill files used
Both methods leaned on the same Bigspin convention stack, mostly pulled in by the self-review subagent rather than the main thread:
Core build: frontend-design (SKILL.md + color-lookup.md, sometimes component-catalog.md) appeared in most runs.
Self-review subagent: bigspin-restrictions, bigspin-code-standards, bigspin-ux-patterns, bigspin-test-patterns, .cursorrules, and CORRECTIONS.md - this caught convention issues (e.g. banned button variants) before they reached the user in several runs.
Pricing: claude-api was loaded during the reporting turn for authoritative rates.
MCP-specific: the Figma MCP server / get_design_context drove the design-to-code conversion; some MCP sessions invoked 0 main-thread Skill-tool skills and still produced accurate output, working straight from the MCP design context.
6. Turns to completion (good enough)
MCP reached good-enough in 1-4 turns with at most one refinement pass (one run needed zero user corrections). Screenshot needed 5-10 change-bearing exchanges, with the build landing first-pass but visual fidelity taking several rounds - one session spent 6 of 10 iterations on the top bar alone.
7. User time to completion
Screenshot averaged ~50 min wall-clock (range ~41-68 min); MCP averaged ~36 min (range ~28-43 min) - roughly 28% faster. Since the developer is in the loop on every correction turn, the correction-round reduction is where most of the human-time savings come from.
8. Correction burden
This is a really clear signal in our data:
User correction rounds: Screenshot ~4.3 avg vs MCP ~0.75 avg.
Design re-uploads: MCP = 0 across all four runs (the design is pulled once via the MCP server and never re-fetched). Screenshot runs required 1 hard re-upload (reference + zoomed crop) plus 2 annotated pink-line clarification shots.
Context restatements: 0 in every session, both methods.
What screenshot got wrong: recurring visual-fidelity misses - top-bar fill/rounding/inset, nav padding & flush-to-top, grey-vs-black copy, button variants, card-tab underline. These are exactly the precise values (tokens, px, node layout) the MCP method gets for free from structured design data.
Final remarks
Using Figma MCP is the way to go when we are bringing Figma designs to life in code! Had we not run this experiment, we would not have realized the dramatic cost difference and the sanity saving value we derive with the MCP.
We did notice some discrepancies between Madeline and Megan’s screenshot to design outputs. Madeline’s first passes were generally better. Better padding, better font spacing, etc. We have poked a little into this, but so far it remains as one of the many mysteries of AI. Dear reader, if you have any ideas for this discrepancy, we are all ears.
Until the next experiment…
Output samples
Original design
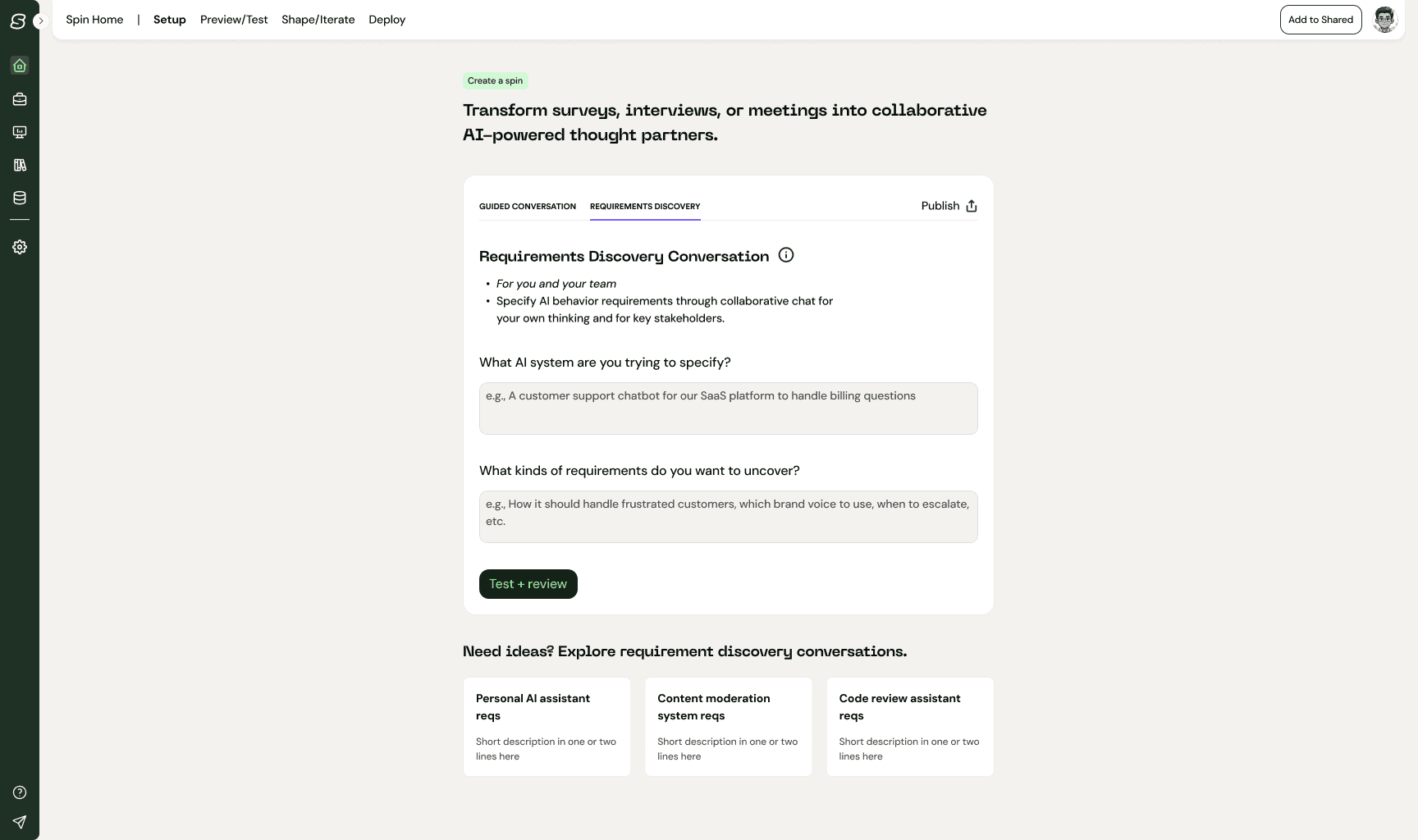
MCP: Cost of build = $23 - Compared to the screenshot, the MCP design, with significantly fewer back and forths, yielded a design that is also much more aligned with the original
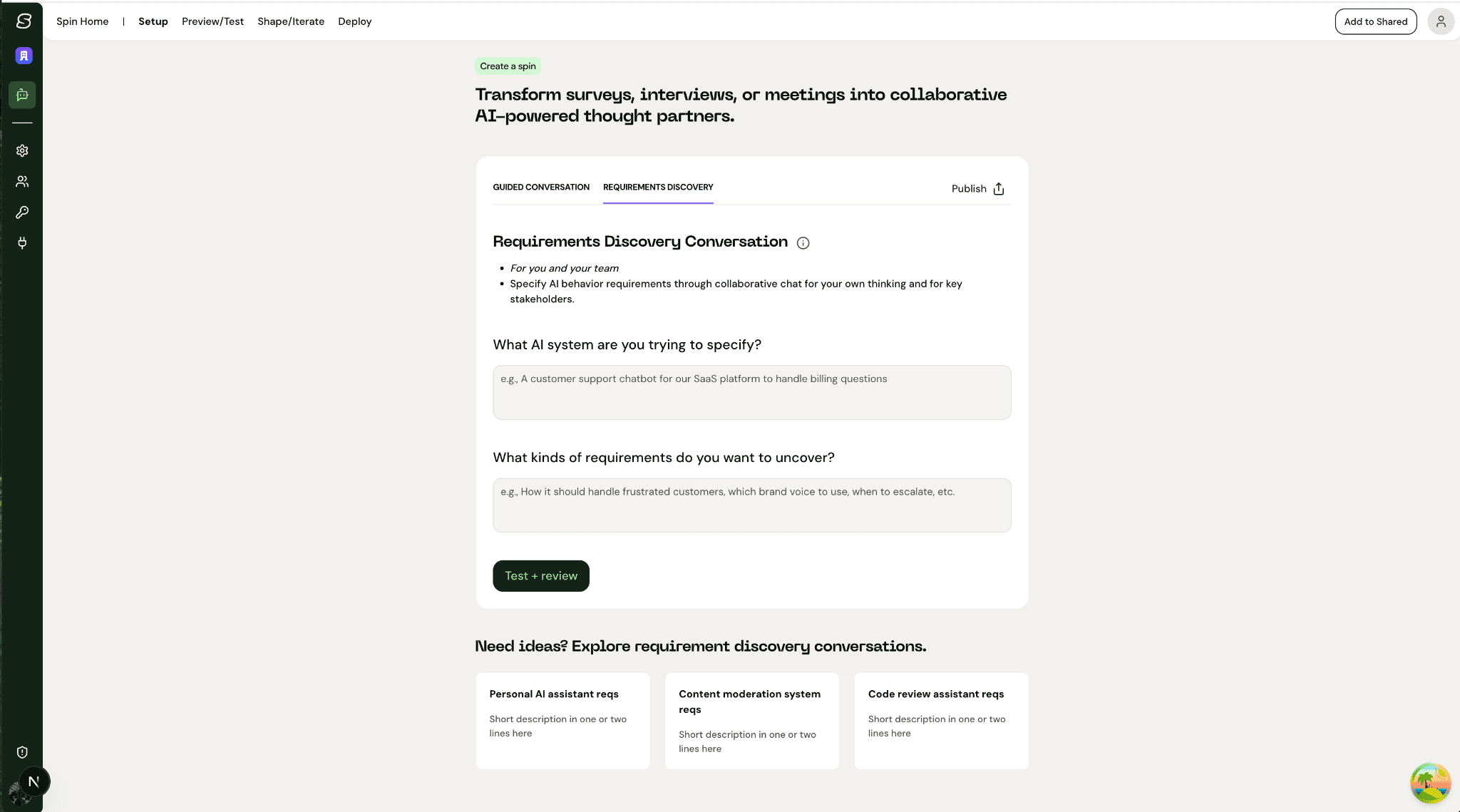
Screenshot: Cost of build = $30 - This barely passes a shippable approval, and this was with a number of user turns telling Claude to make specified improvements. It took so long, the user started really losing steam…
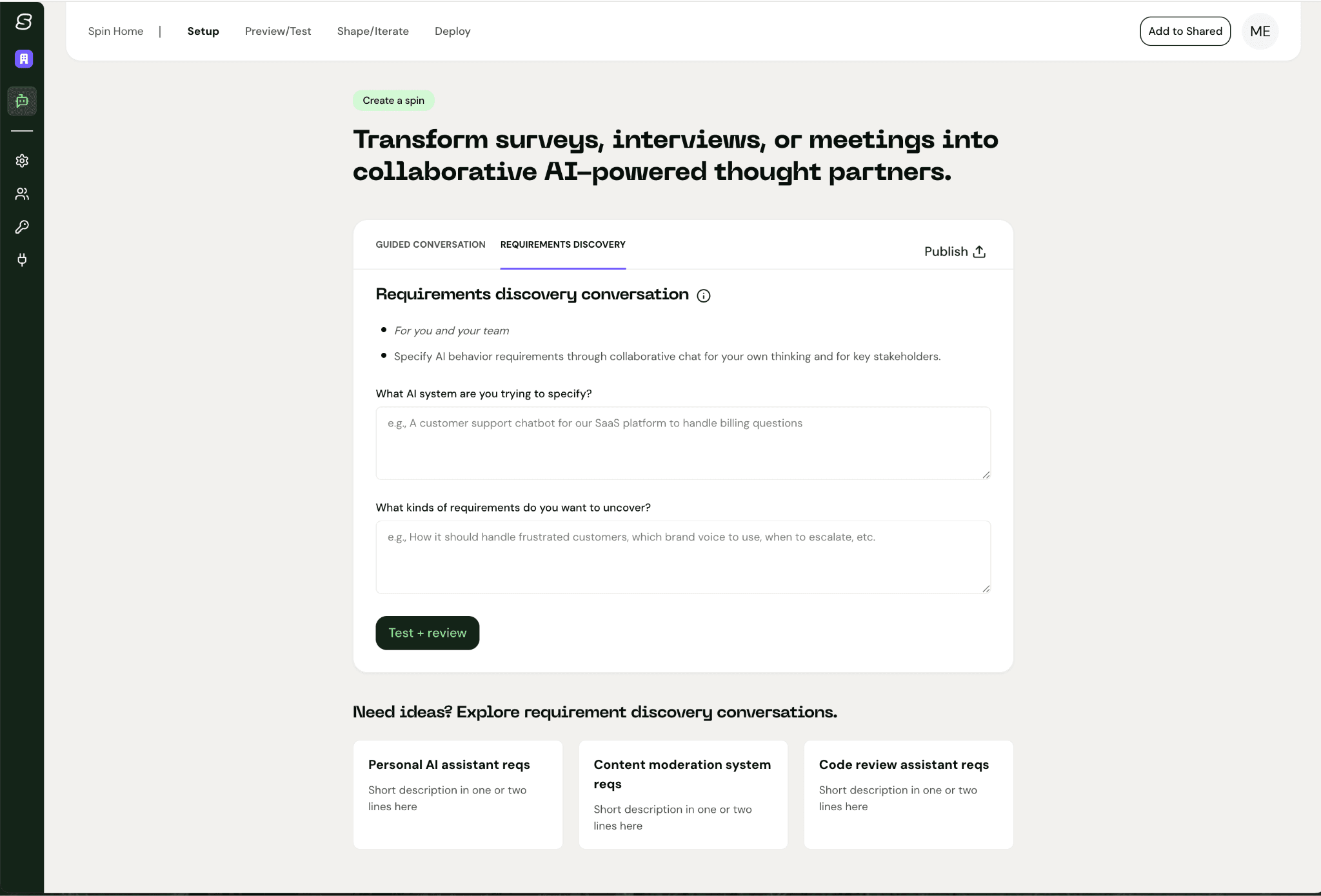
Original
MCP: Cost of build = $32.52
Screenshot: Cost of build = $63 (almost exactly double the MCP) It does include elements that are stronger than the MCP, but it also included 4 additional correction rounds whereas there was only 1 correction round in the MCP