Invisible Failures
Reading time:
2
min
By Christopher Potts and Moritz Sudhof
Most teams building AI products today keep a watchful eye on a wide range of standardized quality signals – e.g., completion rates, response times, user satisfaction scores. These signals are meant to capture the state of the product and help teams home in on systematic failures as they emerge.
Do these quality signals actually provide an accurate picture? Much depends on this question, but it has not been systematically addressed. To begin to fill this empirical gap, we conducted a large-scale study of the WildChat dataset, a collection of over 1M ChatGPT conversations. For WildChat, users were given free access to ChatGPT in exchange for having their deidentified conversations released publicly, making it the largest naturalistic conversational AI dataset available to date.
Our analysis reveals that the standard quality signals are woefully inadequate. Of all the failures we identified in WildChat, 78% produced no visible signal of failure. No corrections, complaints, or abandonment. We call these invisible failures. Luckily, the invisible failures are not random, but rather cluster into recognizable patterns that we can monitor for.
Of all the failures we identified in WildChat, 78% produced no visible signal of failure.
In this post, we provide a high-level overview of the invisible failures our analysis revealed. Our associated research report describes our full methodology, provides numerous examples and additional analyses, and builds a case that these errors will persist even as models become more capable.
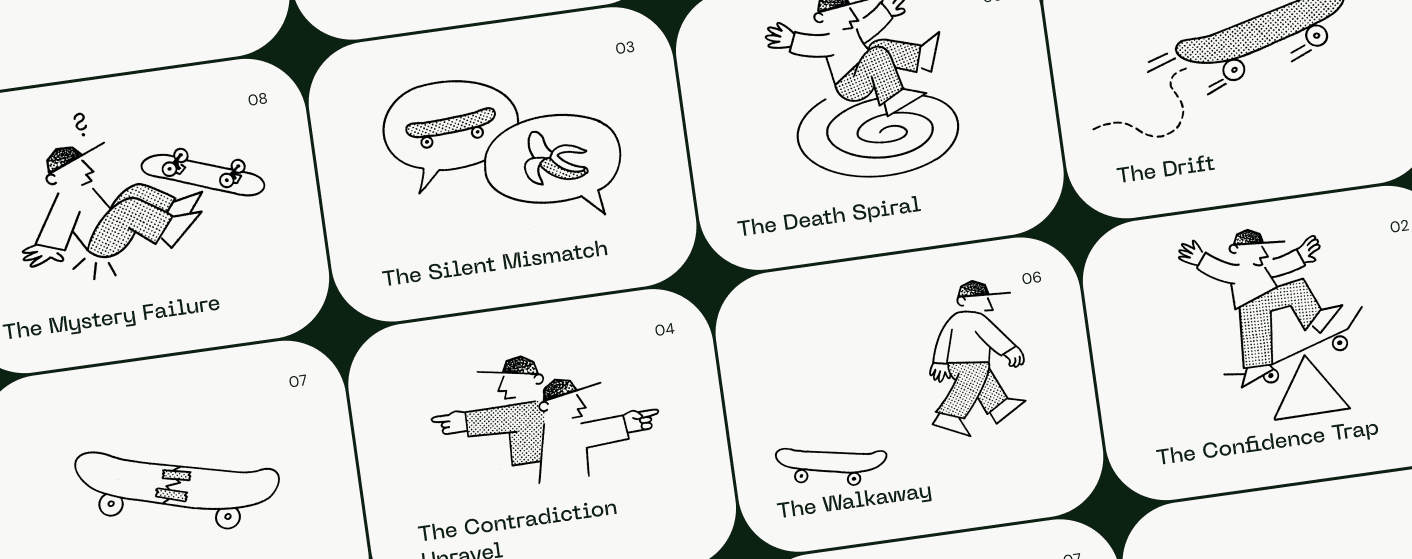
1. The Drift:
The user has a clear goal, and the AI simply addresses a different but related goal. In many instances, Drift is gradual and involves excessive verbosity on the part of the AI, but it can be abrupt as well. The Drift appears across every domain where requests carry enough specificity that a directional misread can go plausibly undetected, and Drift cases alone outnumber the visible failures. 89% of Drift cases are rated poor (task not accomplished or significantly flawed) or critical (task failed with confidently incorrect output that could mislead). (present in 37% of failure cases)
2. The Confidence Trap:
The AI gives a wrong answer with complete confidence, and the user accepts it. This type of invisible failure is especially insidious because it looks so much like a success; very often, the AI anchors its fabrications in real-sounding sources and uses specificity as a proxy for certainty. 96% of Confidence Trap conversations are rated poor or critical, and, like The Drift, The Confidence Trap is more frequent than visible failures. (26% of failure cases)
3. The Silent Mismatch:
The user asks for something. The AI delivers something. The two don't match, but the user accepts the output without pushback, and the conversation ends. The Silent Mismatch is extremely common in exacting technical domains like software development and education, which should haunt conversational AI developers and users alike. 85% of these failures are poor or critical. (9% of failure cases)
4. The Contradiction Unravel:
The AI says X with confidence and then, later in the same conversation, it says not-X with equal confidence. Common sub-types are factual reversals, logic and reasoning inconsistencies, and capability contradictions. Where the user notices these contradictions, we often get an explicit signal from them about a loss in trust, but the majority of instances go unremarked. 97% of these cases are poor or critical, the highest severity of all the categories. (8% of failure cases)
5. The Death Spiral:
The user spots a problem and tries to correct it. The AI doesn't adapt. The user tries a different approach. The AI repeats the same error, or introduces a new one. The conversation loops until the user gives up. 85% of these cases are poor or critical.
(7% of failure cases)
6. The Walkaway:
The user encounters a problem, sees no path to resolution, and leaves. No correction attempt, no escalation, no frustration signal. They simply disappear. These are users you may never see again. 92% of these cases are poor or critical. (6% of failure cases)
In addition to the above, there is a more hopeful category we call The partial recovery (6% of cases). In these cases, the AI takes some missteps but ultimately meets the user's needs. There is also a more problematic class we call The mystery failure (12% of cases), where we know that the user’s goal was not met, but we have not identified additional signals that could explain what went wrong.
These invisible failure patterns provide a much richer and more accurate picture of what is happening with your AI product than the traditional quality signals ever could. If you're developing an AI product, you're probably reading lots of transcripts, and so you've seen the patterns already. Bigspin provides the instrumentation layer that you need to scale these analyses. With Bigspin, you get visibility into your users’ experiences and direct help with implementing system improvements based directly on data.









